
Uncategorized
Fewer changes are faster to deploy than fewer changes
Itamar Turner-Trauring, Incremental results: how to succeed at large software projects:
- Faster feedback...
- Less unnecessary features...
- Less cancellation risk...
- Less deployment risk...
👏 👏 👏 👏 👏 read the whole thing, Itamar’s tale is well told.
Consider: incremental approaches consist of taking a large scope and finding smaller, still-valuable scopes inside of it. Risk is 100% proportional to scope. Time-to-deliver grows as scope grows. Cancellation and deployment risk grow as time-to-deliver grows. It’s not quite math, but it is easy to demonstrate on a whiteboard. In case you happen to need to work with someone who wants large scope and low risk and low time-to-delivery.
TIL: divide by 10 with this one weird number
Running an application across two physical databases is not a straightforward thing. One of the relatively easier ways to do it involves assigning each database instance a shard number and then arranging for all your primary key IDs to end with that number. For example, shard 0 generates IDs like 1230, 40, 482340, shard 1 generates IDs like 1231, 41, 482341, and shard 2 generates IDs like 1232, 42, 482342, etc. all the way up to 9. If you want more than 10 database shards, it gets more involved.
My brain is wired oddly, so I came to wonder how you would quickly get the shard ID for an ID (e.g. shard 1 for 1231). This is really easy with decimal math; you just divide by 10. However, we run our databases on computers that can only do binary math, so its not actually simple.
But it turns out you can do it quite fast! There’s one weird number, expressed as <code>0x1999999A hexadecimal, that is very close to multiplying by the fraction 1/10 (plus further binary math and register trickery). Thus you can do this in only a few instructions on Intel processors released in the past twenty years.
I’m really glad someone else figured this out.
OAuth2 🔥-takes
Is it too late to do hottakes for something that’s been around for nearly a decade?
OAuth2 pros:
- I can allow other sites to use my data with some confidence that, at least, my authentication information won't leak
- It has made really cool stuff possible at my current workplace and workplace-2
- Libraries to make it happen in server-side apps are pretty good
Cons:
- There are a bajillionty implementations and standard definitions of OAuth2 (for somewhat justifiable reasons)
- If you want to tinker with an OAuth2 API, you're in a bit of hurt because you can't just grab a token and start playing (mostly, depending on the implementer)
- Those open source libraries are the kind of thing that drive maintainers away pretty quickly 😬
Overall: would not uninvent this technology.
The emotional rollercoaster of extracting code
There’s a moment of despair when extracting functionality from a larger library, framework, or program. The idea grows, a seed at first and then a full-blown tree, that the coupling in this functionality isn’t all bad. A lot of people talk only about coupling and leave out cohesion. They aren’t mutually exclusive! When the two are balanced, it’s hard to come up with a reason to start extracting.
On the other hand, sometimes that moment of despair strikes when you start really digging into the domain and realize this chunk of functionality isn’t what you thought it was. Maybe it’s not coherent (see above!) or perhaps the model of the domain isn’t deep enough. This is a pretty good signal to hit the brakes on the refactoring, figure the domain out, and reconsider the course of action.
Feature envy rears its head in extractions too. Patterns of crosstalk between the existing thing and the new thing are a sure sign of feature envy. It’s tempting to say, hey maybe you really need a third thing in the middle. That’s probably making matters worse though.
That said, changing bidirectional communication to unidirectional is usually a positive thing. Same for replacing any kind of asynchronous communication with synchronous. Or replacing lockstep coordination with asynchronous messaging. Envy is tricky!
(I) often encourage starting a new service or application within your existing “mothership”. The trendy way to say this right now is “monorepo all the things” or build a “modular monolith”. I find this compelling because you can leverage a lot of existing effort into operationalizing, tooling, and infrastructure. Once you know the domain and technical concerns specific to the new thing, you can easily extract into its own thing if you need to. The other edge of a monorepolith is that path dependence is a hell of a thing. Today is almost certainly an easier day to split stuff out than tomorrow.
A thing to consider pursuing is a backend-for-frontend service in pursuit of a specific frontend. It doesn’t even have to serve an application. You may have services that are specific to mobile, desktop, apps, APIs, integrations, etc. Each of these may need drastically different rates of change, technical features, and team sets.
Probably don’t split out a service so that a bunch of specialized people can build a “center of excellence” for the rest of the organization to rely upon. This is a very fancy way to say “we are too cool for everyone else and we just can’t stand the work everyone else is doing”. On their best day, the Excellence team will be overwhelmed by the volume of work they have put in front of themselves to make Everything Good. On their worst day, they will straight give up.
If you split something out, realize you’re going to have to maintain it until you replace it. And you’re going to rebuild the airplane while it’s flying. If you’re not really into that, stop now. Just because you can’t stand Rails, relational databases, or whatever doesn’t mean you should jump into an extraction.
More ideas for framework people
A few months ago I wrote about Framework and Library people. I had great follow-up conversations with Ben Hamill, Brad Fults, and Nathan Ladd about it. Some ideas from those conversations:
use a well-worn framework when it addresses your technical complexities (e.g. expose functionality via the web or build a 3-d game) and your domain complexity (e.g. shopping, social networking, or multi-dimensional bowling) is your paramount concern
once you have some time/experience in your problem domain, start rounding off corners to leave future teammates a metaframework that reduces decision/design burdens and gives them some kind of golden path
frameworks may end up less useful as integration surface area increases
napkin math makes it hard to justify not using a framework; you have to build the thing and accept the cost of not having a community to support you and hire from
to paraphrase Sandi Metz on the wrong abstraction: “(Using) no abstraction is better than the wrong abstraction”; if you’ve had a bad time with a framework, chances it was an inappropriate abstraction or you used the abstraction incorrectly
Did you try editing the right file?
The first few years of my career, I edited the wrong file all the time. I could spend hours making changes, wondering why nothing was happening, until I realized I’d been tinkering in the wrong place because I was misreading a file path or not paying close enough attention to control flow.
Fast forward to now, and I’m pretty quick to drop a raise “BLORP” in code I’m tinkering with if things aren’t working like I think they should. All hail puts debuggerering.
However, it turns out I found a new class of this operator error today. I was diligently re-running a test case, expecting new results when the test fixture file I thought was changed was the wrong file. Once I deleted the right file, I was back on my way.
Joyful and grumpy are we who can find new ways to screw up time ever day!
Chaining Ruby enumerators
I want to connect two Ruby enumerators. Give me all the values from the first, then the second, and so on. Ideally, without forcing any lazy evaluations and flat so I don’t have to think about nested stuff. Like so:
xs = [1, 2, 3].to_enum ys = [4, 5, 6].to_enum [xs, ys].chain.to_a # => [1, 2, 3, 4, 5, 6]
I couldn’t figure out how to do that with Ruby’s standard library alone. But, it wasn’t that hard to write my own:
def chain(*enums)
return to_enum(:chain, *enums) unless block_given?
enums.each { |enum| enum.each { |e| yield e } }
end
But it seems like Ruby’s library, Enumerable in particular, is so strong I must have missed something. So, mob programmers, is there a better way to do this? A fancier enumerator-combining thing I’m missing?
Stored Procedure Modern
The idea behind Facebook’s Relay is to write declarative queries, put them next to the user interaction code that uses them, and compose those queries. It’s a solid idea. But this snippet about Relay Modern made me chuckle:
The teams realized that if the GraphQL queries instead were statically known — that is, they were not altered by runtime conditions — then they could be constructed once during development time and saved on the Facebook servers, and replaced in the mobile app with a tiny identifier. With this approach, the app sends the identifier along with some GraphQL variables, and the Facebook server knows which query to run. No more overhead, massively reduced network traffic, and much faster mobile apps.Relay Modern adopts a similar approach. The Relay compiler extracts colocated GraphQL snippets from across an app, constructs the necessary queries, saves them on the server ahead of time, and outputs artifacts that the Relay runtime uses to fetch those queries and process their results at runtime.
How many meetings did they need before they renamed this from “GraphQL stored procedures” to “Relay Modern”?
(FWIW, I worked on a system that exposed stored procedures through a web service for client-side interaction code. It wasn’t too bad, setting aside the need to hand write SQL and XSLT.)
Feedback: timing is everything
With feedback, like jokes, timing is everything. Good feedback at a bad time won’t do the trick.
I’ve mostly experienced programming feedback through pull requests. This is way better than no feedback. However, since most pull requests occur at the end of work, and not somewhere in the middle, some kinds of feedback are not conducive to pull requests.
Suppose all feedback falls somewhere on two axes: “timeliness” and “depth”. The narrow sweet spot of code review is apparent:
[caption id=“attachment_4302” align=“alignnone” width=“861”]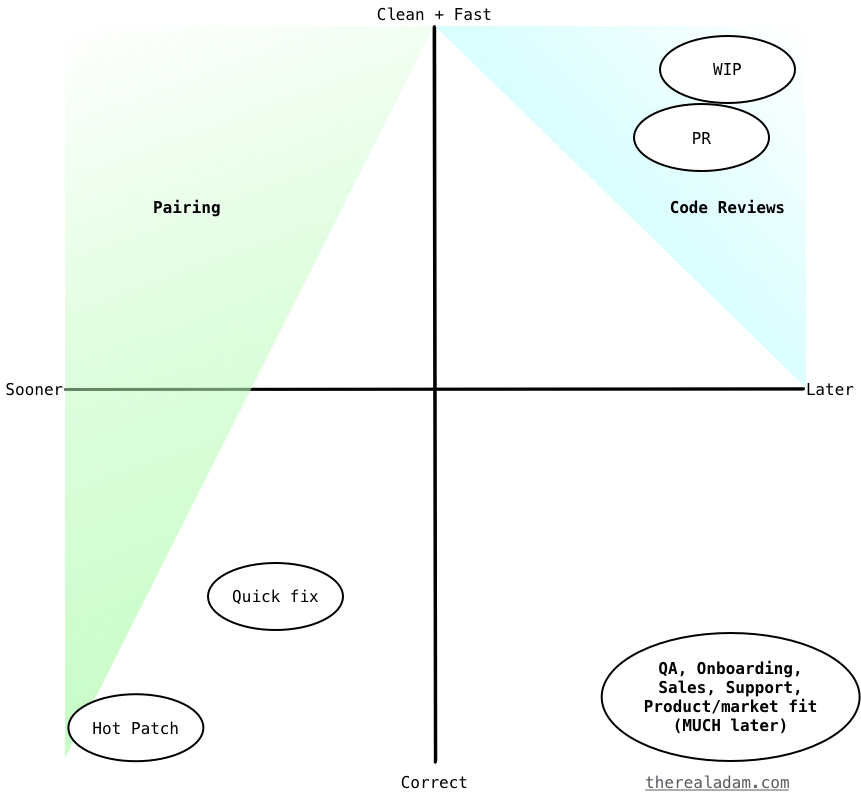 Pairing and code review are not so similar[/caption]
Pairing and code review are not so similar[/caption]
The sweet spot in the top-right corner is when code review works best: unhurried and in-depth feedback. I’d hesitate to call the lower-right corner of hurried, minimal feedback a code review at all; it’s more like rubber stamping.
I’ve often referred to code review, flippantly, as the worst form of pairing yet invented. I’ve given a lot of code review feedback in the past that was better suited to the synchronous nature of pairing than the very asynchronous nature of code reviews. That said, I feel like pairing is an excellent way to give all manners of feedback in the moment the code is being conceived or written. You can immediately point out possible incorrectness or better designs and talk it out, with the code at hand, with your collaborator.
However, we can’t all pair all the time. Let me show you how I’m trying to better time my feedback when I can’t share it immediately.
A tale of four pull requests
Consider four PR subject lines. Which ones are appropriate for architectural ideas? What about optimization ideas? When is deep refactoring feedback appropriate? Can I look at one of these in an hour when I’m done with my current task?
- “Hotfix Facebook Auth scope”
- “Prevent sending email for failed payment jobs”
- “Add tagging to admin storylines listing”
- “WIP introduce Redis/Lua-based story indexing”
Lately, when I do pull request reviews, I use these guidelines:
- Figure out if this PR seems like it’s a hot patch to production, a quick fix on existing work, a PR landing new functionality, or a work-in-progress checkpoint seeking feedback.
- Bear in mind that hot patches and quick fixes are more time sensitive and need yes/no feedback on correctness more than detailed feedback.
- For hot patches (e.g. “Hotfix FB auth”), I’m only looking for “is this correct” and “will it fix the problem?”; thumbs up or thumbs down and commentary as to what I think is missing to solve the problem. No refactoring ideas. I only touch on performance if I spot a regression.
- For quick fixes (e.g. “Prevent sending email…”), I’m again looking for correctness and timeliness. I might leave ideas for how to improve the performance or cleanliness of the code later. Those kinds of notes are entirely up to the gumption of the other developer, though. I know the low-gumption feeling of wanting only to fix something and get on to the next thing.
- Landing new functionality (e.g. “Add tagging…”) receives a full review cycle. Beyond baseline correctness, I’m trying to view this code through my crystal ball. When some value of
Nis grows, will this code slow down noticeably? Is the code structured so that future changes are easy and obvious? - Work-in-progress checkpoints (“WIP introduce Redis/Lua…”) are open to the full spectrum of feedback. Ideas for how to differently structure data, which APIs to export, how to structure objects, how to name the domain model, etc. are all in play. Pretty much the only thing out of play is anything that feels too close to bike shedding.
- Bear in mind that everyone exists on a spectrum of coding specificity. More seasoned developers are likely open to ideas for restructuring code or considering novel approaches. Less seasoned developers (including seasoned developers new to the team) likely want specific guidance about which changes to make or factors they need to consider.
- Where I may try to respond to hot patches and quick fixes in less than fifteen minutes, I may wait a couple hours before I look at new functionality or WIP reviews.
- The most difficult part with these guidelines is how to handle ideas about refactoring on time-sensitive reviews. I want to hold the line against letting lots of little fixes accrete into a medium-sized mess. I don’t want to discourage ideas for refactorings either; I want them separately so I can act on them when I have the energy to really do them.
In short
Use different tactics when sharing feedback for code review; it’s not pairing. Identify patches, reviews, and full feedback pull requests. Sanity check patches, look for correctness in review, look for design in review. Use GitHub’s review process to indicate your feedback is “FYI” vs. “fix this before merging”. Time-to-response is most important for patches and fixes.
Above all: giving feedback is a skill you acquire with practice, empathy, and maintaining a constructive attitude.
Practically applying Clojure
Fourteen Months with Clojure. Dan McKinley on using Clojure to build AWS automation platform Skyliner:
The tricky part isn’t the language so much as it is the slang.
Also, the best and worst part of Clojure:
When the going gets tough, the tough use maps
This is probably better now that specs and schema are popular. Before, when they were mysterious maps full of Very Important State, reading Clojure code (and any kind of Lisp) was pretty challenging.
Make sure you stick around for the joke about covariance and contravariance. Those type theories, hilarious!
Lessons on software complexity from MS Office
I learned a lot of things from Complexity and Strategy by Terry Crowley:
In Fred Brooks’ terms, this was essential complexity, not accidental complexity. Features interact — intentionally — and that makes the cost of implementing the N+1 feature closer to N than 1.
In other words, the ability to change a product is directly proportional to the size of N (features, requirements, spec points, etc.) for the system that express that product. You may find practices that multiply N by 0.9 so you go a little faster. You may back yourself into a corner that multiply N by 1.1 so you go a little slower. But, to borrow again from Fred Brooks, there is no silver bullet. Essential domain complexity is immutable unless you reduce the size of the domain, i.e. cut existing features.
Not even fancy new technologies are correlated with reducing your multiplier, in the long run:
This perspective does cause one to turn a somewhat jaundiced eye towards claims of amazing breakthroughs with new technologies...What I found is that advocates for these new technologies tended to confuse the productivity benefits of working on a small code base (small N essential complexity due to fewer feature interactions and small N cost for features that scale with size of codebase) with the benefits of the new technology itself — efforts using a new technology inherently start small so the benefits get conflated.
Lastly, this is a gem about getting functionality “for free”:
So “free code” tends to be “free as in puppy” rather than “free as in beer”.
All free functionality eventually poops on your rug and chews up your shoes.
Type tinkering
I’m playing with typeful language stuff. Having only done a pinch of Haskell, Scala, and Go tinkering amidst Ruby work over the past ten years, it’s jarring. But, things are much better than they were before I started with Ruby.
Elm in particular is like working with a teammate who is helpful but far more detail oriented than myself. It lets me know when I missed something. It points out cases I overlooked. It’s good software.
I’ve done less with Flow, but I like the idea of incrementally adding types to JavaScript. The type system is pragmatic and makes it easy to introduce types to a program as time and gumption permit. Having a repository of type definitions for popular libraries is a great boon too.
I’m also tinkering with Elixir, which is not really a typed thing. Erlang’s dialyzer is similar in concept to Flow, but different in implementation. Both allow gradually introducing types to systems.
I’m more interested in types stuff for frontends than backends. I want some assurance, in the wild world of browsers and devices, that my systems are soundly structured. Types buy me that. Backends, I feel, benefit from a little more leeway, and are often faster to deploy quick fixes to, such that I can get away without the full rigor of types.
Either way, I’m jazzed about today’s tools that help me think better as I build software.
Universes from which to source test names
A silly bit of friction in writing good tests is coming up with consistent, distinctive names for the models or object you may create. Libraries that generate fake names, like Faker, are fun for this, but they don’t produce consistent results. Thus I end up thinking too hard.
Instead, I like to use names from various fictional-ish universes:
- Wile E. Coyote and the Road Runner: Acme Corp, Ajax, Fleet Foot corp. etc. Bonus: read through the extensive laws and rules of this universe!
- Mickey Mouse universe: you can't go wrong with putting Disney trademarks in your code.
- CIA cryptonyms: when I want my teammates to wonder if they know everything going on with our project.
Hopefully my teammates enjoy these little easter eggs as much as I enjoy looking them up when I need something fancier and less dry than metasyntactic variables.
You should practice preparatory refactoring
When your project reaches midlife and tasks start taking noticeably longer, that’s the time to refactor. Not to radically decouple your software or erect onerous boundaries. Refactor to prepare the code for the next feature you’re going to build. Ron Jeffries, Refactoring – Not on the backlog!
Simples! We take the next feature that we are asked to build, and instead of detouring around all the weeds and bushes, we take the time to clear a path through some of them. Maybe we detour around others. We improve the code where we work, and ignore the code where we don't have to work. We get a nice clean path for some of our work. Odds are, we'll visit this place again: that's how software development works.
Check out his drawings, telling the story of a project evolving from a clear lawn to one overwhelmed with brush. Once your project is overwhelmed with code slowing you down, don’t burn it down. Jeffries says we should instead use whatever work is next to do enabling refactorings to make the project work happens.
Locality is such a strong force in software. What I’m changing this week I will probably change next week too. Thus, it’s likely that refactoring will help the next bit of project work. Repeat several times and a new golden path emerges through your software.
Don’t reach for a new master plan when the effort to change your software goes up. Pave the cow paths through whatever work you’re doing!
Let's not refer to Ruby classes by string
I am basically OK with the tradeoffs involved in using autoloading in Rails. I do, however, rankle a little bit at this bit of advice in the Rails guide to developing engines.
[caption id=“attachment_4216” align=“alignnone” width=“661”]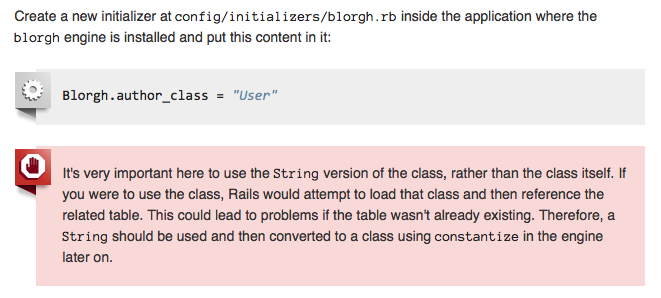 Screencapture from Rails Guide to Engines[/caption]
Screencapture from Rails Guide to Engines[/caption]
In short, when configuring an engine from an initializer, you’re supposed to protect references to autoloaded application classes (e.g. models) by encoding them as strings. Your engine later constantizes the string to a class and everything is back to normal.
A thing I am not OK with is “programming with strings”. As an ideal, strings are inputs from other machines or humans and internal references to code are something else. In Ruby, symbols fill in nicely for the latter. Could I refer to classes as Symbols instead of Strings and live with the tradeoffs?
Well it turns out, oddly enough, that Rails is pretty sparing with Symbol extensions. It has only 120 methods after Rails loads, compared to 257 for String. There are no specific extensions to symbol, particularly for class-ifying them. Even worse (for my purposes), there isn’t a particularly great way to use symbols to refer to namespaced classes (e.g. Foo::Bar).
But, the Rails router has a shorthand for referring to namespaced classes and methods, e.g. foo/bar#baz. It doesn’t bother me at all.
In code I have to work with, if at all possible, I’d rather refer to classes like so:
- Refer to classes by their real ClassName whenever possible given the tradeoffs of autoloading
- When autoloading gets in the way, refer to things by symbols if at all possible
- If symbols aren’t expressive enough, use a shorthand encoded in a string, e.g.
foo/bar#baz - … (alternatives I haven't thought of yet)
- Refer to classes by their full string-y name
But, as ever, tradeoffs.
Your product manager could save your day
I thought the feature I’m working on was sunk. An API we integrate with is, let us say kindly, Very Much Not Great. Other vendors provide an API where we can request All The Things and retrieve it page by page. This API was not nearly so great, barely documented, and the example query to do what I needed didn’t even work.
Sunk.
Luckily, only an hour in, I rolled over to the product manager and asked if it was okay if we were a little clever about the feature. We couldn’t request All The Things, but we could request Each of The Things that we knew about. It wasn’t great, but it was better than sunk.
The product manager proceeded to tell me that was okay and in fact that’s kind of how the feature works for other APIs too. I hadn’t noticed this because I was up to my neck in code details. She described how this feature is used in out onboarding process. It wouldn’t matter, at that level, whether we made a dozen requests or a hundred.
I wrote basically no code that day. Someone who “crushes code” or “moves fast and breaks things” would say I didn’t pull my weight. Screw ‘em.
I didn’t go down a rabbit hole valiantly trying to figure out how to make a sub-par API work better. I didn’t invent some other way for this feature to work. My wheels were spinning, but only for a moment.
Instead, I worked with the team, learned about the product, brainstormed, and figured out a good way forward. I call it a very productive day.
The occurrence and challenge of ActiveRecord lookup tables
I’ve noticed lots of Rails apps end up with database-backed lookup tables. Particularly in systems with some kind of customer or subscription management, it’s almost guaranteed that User or Customer models belong_to SubscriptionLevel or Plan models. Thus, you frequently need to query both models.
If you’re looking for avoidable database work, as I sometimes have, this seems like low-hanging fruit. Plan level models very rarely change. You could replace those Plan or SubscriptionLevel models with a hardcoded data object and move on.
In my experience, you now have a white whale on your hands. This low-hanging fruit may haunt you for a while. It could cause you to invent increasingly implausible mechanisms for ridding yourself of this “technical debt” (scare quotes, it’s a trade-off and not actual technical debt). Teammates will appear drowsy when you mention this problem and its technical details, then back away slowly.
Why is it so tricky to convert AR database lookups to non-AR in-memory lookups?
I’ve attempted this twice. Both times, I tried to grab as little surface area as possible and ended up with nearly all of the models. A current teammate is trying now and suffering a somewhat similar fate. They’re more detail-oriented and motivated than I am, so I hope they’ll succeed. (Ed. they succeeded!)
Is this phenomenon something we can easily write off to coupling or is it something else? My pessimistic, gossip-y sense leads me to think people who have become ORM Skeptic went down this path thinking it’s inevitable if you accept an ORM into your life. They came away a dark shade of who they were with the conclusion that ORMs ruin everything. However, the phases of coping that involve a three thousand word essay and then writing a new database layer thing don’t actually solve this problem.
In the ActiveRecord flavor of ORMs, it is easy to describe model graphs and interactions amongst those graphs. Once you’ve got the whole model graph, its often difficult to isolate a subsection of it. AR, in particular, can make it easy to violate Demeter and reach through that graph in hard-to-refactor ways.
Our lack of great and general tools for working with Ruby code that uses these graphs and rewriting said code is another big challenge. Solving these problems requires visualizing the direct and transitive connections between models. Then you need some kind of refactoring tool to rewrite code to use an indirection object instead of directly coupling. We lack both of those in the Ruby world.
Optimistically, I’d think this is a case of refactoring smarter. Given a solid test suite you could:
- connect your lookup models to an in-memory SQLite database populated at app start, no need to remove ActiveRecord
- use one of the several libraries that implement enough of the ActiveRecord interface to replace models with classes backed by static data
- lots of things I haven't thought or heard of!
The thing you wouldn’t want to do, and where I faltered at least once, was to let it become a long-running task. When you’re making changes all over the code base, any amount of churn behind your back is potentially crippling. If you can freeze the code base, I highly recommend it. (Coincidentally, this is exactly what my smarter-than-me teammate did!)
The other thing to keep in mind is that, inevitably, you will come across weird uses of ActiveRecord and Rails that you didn’t know about, are pretty sure you don’t like, and have to work with anyway. Set aside time for these known unknowns.
When dealing with potentially large, radical changes to your application code, how radical are you willing to go to make many smaller changes than one big one? There’s no crisp answer here. All code grows awkward in different ways. As always: divide, conquer, and celebrate your victories!
The right way and the practical way
Brent Simmons, Reason Number 33,483 to Hate Programming:
Or I could have the superclass expose the appIsTerminating property in its header file, so that the subclass could see it. This also sucks, because a controller class has no business exposing its own copy of global application state.
In the end, though, that’s what I did. (Along with a comment that the property was there for subclasses.)
It reminds me that there are two competing values:
Do everything the right way every time.
Make responsible and professional decisions about time and expenses and benefits and drawbacks.
My nature is to take path #1. It is so hard for me to take path #2. I have the utmost respect who can work on sprawling, modern software and stay on path #2. But path #1, always pulling me in and sending me down rabbit holes.
Sometimes I wonder which of these paths got me to where I am in my career. Others, I wonder if I think I’m a everything-the-right-way person but really I’m a responsible-and-professional-tradeoffs person.
A brain’s a weird place to live.
Framework and Library people
By unscientific survey, I think many developers would prefer to work in a “framework world” where many decisions of principle and organization are passed down by a vendor or architecture team. Think Rails/Django/Laravel for backends, Ember/Elm for frontends, Unity for games. These are the Framework people.
Fewer developers would prefer to create their own world, building up tools and libraries to suit. They select a few first principles and build their own world. They’re the bebop jazz musician, eschewing big band gigs and music people can dance to to create their own intellectual world. These are the Library people.
I’m a Framework person. The allure of Library people sometimes tempts me after I look at a beautifully-restored car or a well-structured song. But constructing a library world is thankless and not particularly high leverage, unless you succeed in creating something for framework people. Weird, eh?
Empathy Required
Nearly fourteen years ago, I graduated college and found my first full-time, non-apprentice-y job writing code. When I wrote code, these were the sorts of things I worried about:
- Where is the code I should change?
- Is this the right change?
- What are the database tables I need to manipulate?
- Who should I talk to before I put this code in production?
Today, I know a lot more things. I did some things right and a lot of things wrong. Now when I write code, these are the sorts of things I worry about:
- Am I backing myself into a corner by writing this?
- Why was the code I'm looking at written this way and what strategy should I use to change it?
- Will this code I just wrote be easy to understand and modify the next time I see it? When a teammate sees it?
- Should I try to improve this code's design or performance more, or ship it?
Half of those concerns are about empathy. They’re only a sampling of all the things I’ve learned I should care about as I write code, but I think the ratio holds up. As I get better and better at programming, as my career proceeds, I need more empathy towards my future self and my teammates.
Further, that empathy needs to extend towards those who are less experienced or haven’t learned the precise things I’ve learned. What works for me, the solutions that are obvious to me, the problems to steer clear of, none of that is in someone else’s head. I can’t give them a book, wait three weeks, and expect them to share my strengths and wisdoms.
That means, when I advise those who listen or steer a team that allows me to steer it, I have to make two camps happy. On one hand, I have to make a decision that is true to what I think is important and prudent. On the other hand, I have to lay out guidelines that lead the listener or teammate towards what I think is important or prudent without micromanagement, strict rules, and other forms of negative reinforcement.
It’s so easy, for me, to just hope that everyone is like me and work under that assumption. But it’s much better, and highly worthwhile, to figure out how to help friends and teammates to level up on their own. It requires a whole lot of empathy, and the discipline to use it instead of impatience. Worth it.