
A low-road LLM prototype, with FastHTML
I wanted to tinker with llm and “AI engineer” up a humble tool for working with my notes, writings, highlights, etc. Emphasis on humble: if I could tinker with any one of those datasets quickly and iteratively, I would mark it as a win. (Previously, Scaling down native dev.) Medium story short, I exported some of my reading highlights, loaded it into a database, and wrapped a quick UI around it to navigate my highlights via embeddings rather than keyword search. A few short sessions later, maybe a few hours total, I had something interesting working. 💪🏻
1. Data
For several years, I’ve used Readwise to capture highlights and search/review them later. Handily, Readwise has CSV (and tree-of-Markdown files) exports of all one’s highlights. As data formats go, CSV is nearly perfect for this exercise. It’s structured, so parsing is not required to shoehorn it into a low-ceremony data pipeline. That said, Readwise’s export isn’t perfect: notably it lacks URLs the highlights started with. But for experiments, it’s a start.
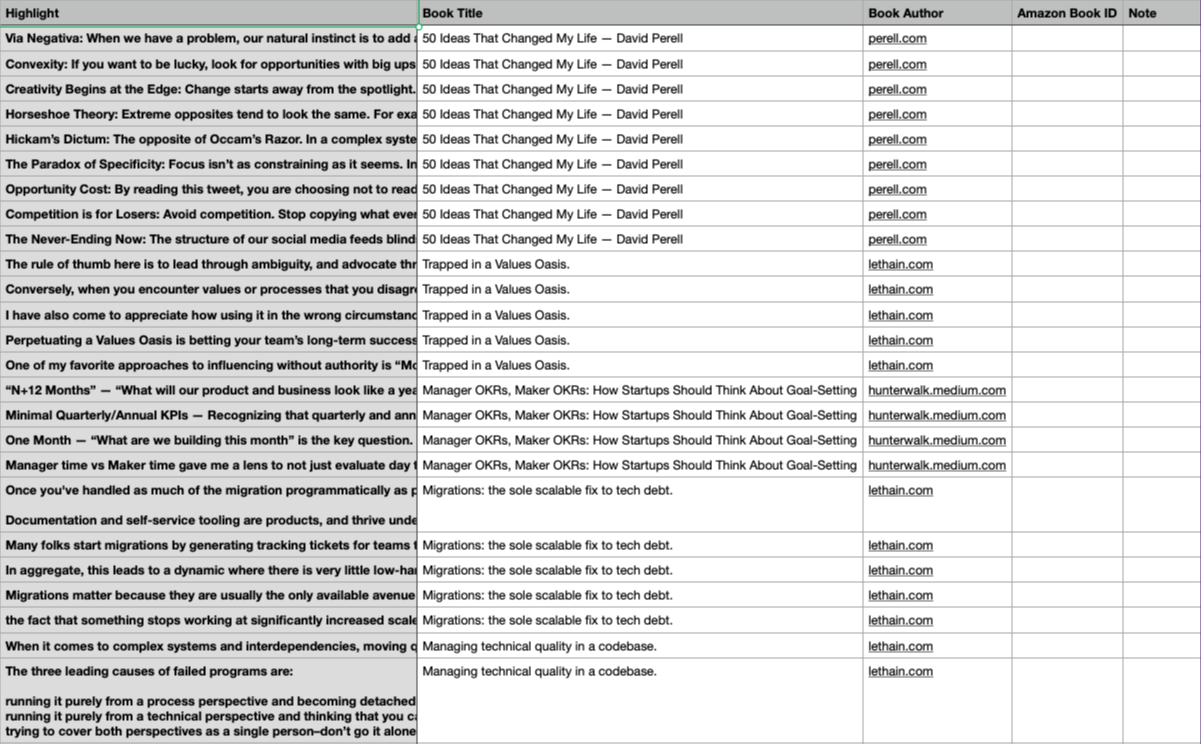
2. Pipeline
Thanks to sqlite-utils, I can generate a SQLite database from the export CSV. This all happens by convention with the sqlite-utils command line.
db:
sqlite-utils insert \
highlights.db \
highlights \
data/readwise-data-2.csv \
--csv \
--pk id
No bespoke (Python) code is required in this whole pipeline process. I ended up encapsulating the steps in a Justfile, but anything that can run shell commands would have done the trick.
Step two is to generate embeddings. With the right install, this is another one-liner, this time with llm. We query the database generated in the previous step to give us content to pass through to a text embedding model. The generated vectors are stored into the same SQLite database.
embed:
llm embed-multi \
docs \
--database highlights.db \
--store \
--sql 'select id, highlights."Book Title" as title, highlights."Highlight" as content from highlights' \
--model mpnet
There is no step three! The data is ready to query for “semantic”, not keyword, similarity search. To prove to myself I had an end-to-end working proof of concept, I used this snippet to query the data:
# $ just query "now is not the time for notes"
query q:
llm similar \
docs \
--database highlights.db \
--content '{{q}}'
3. Prototype
Next, I put it all together in a FastHTML app. This was fun! FastHTML is great for this kind of bespoke, informal hacking. Caveat, some of this may not be idiomatic Python. I’m just coming back to Python after not having written it in seriousness for twenty years.
- Using the
dataclassdecorator on a class and a method for converting an object to a “FastTag”, love this for low-ceremony but typed data modeling. - I finally got the grasp of Python’s generator syntax. I want to like
itertools, but it’s a pain to use. (🌶️ Ruby’sEnumerableremains undefeated.) - JSX-like syntax to structure UI in code is great. This approach falls down every time I put a designer in front of an editor, but I’m going to call it: this is the mark-up/UI-construction ergonomics developers crave.
- There’s no need for a layered web-app approach here. There’s a
similarfunction that turns query text into similar highlight “model” objects. That’s a nice affordance for working quickly and loosely.
Conclusions
Python’s has pleasant things going on lately. Even a career Ruby developer like myself can find kind things to say. 😉
The trickiest part to building with LLMs and generative AI is source data. Prompting a model as-is is not much more interesting than using ChatGPT or Claude. Ergo: look to one’s notes, posts, highlights, etc. to find compelling data to build upon.
Variations on RAG (this is probably a bit short of calling itself RAG, but it’s very close) produce more appealing results than keyword indexing, but not by much. I don’t think it’s the center of a product yet; more of a sidebar or enhancement.
All of this took less than five hours to build. I’ll probably end up spending a couple of hours total writing it up. This is the kind of “working with the garage door up” kind of thing I want to do. 💯📈